 Tweet
Tweet
หืมตาลายเลยว่างๆๆมาช่วยแปลนะครับท่าน SSK
-
-
มีข่าว RisV Foundation มาอีกร้อนแรงจริงๆๆ
พร้อมๆๆกับ ข่าว ARm เดะมาอัพเดทอีกทีครับเห็นแว้บๆๆในมือถือละ
ช่วงนี้ไงก็ มือถือ 5G ทยอยกันก่อน ViVO3S 5G

เน็ต 5G แรงกว่า 4G สิบเท่าทีเดียว ตัวนี้ Snap 865Last edited by micronz; 23 Aug 2020, 05:16:29.Comment
-
โอ้ว เย่ห์ โลก เรามีระบบปฏิบัติการเสรีอย่าง Linux ที่ใช้ฟรี
CPU ที่เสรีแท้ยังมีอยู่ ตอนนี้ที่น่าจับตาสุดก็คือ Risc V ตอนนี้ผู้ร่วมโครงการมาเพียบครับ
Qualcom และ ล่าสุด REdhat หรือ IBM
https://www.techtalkthai.com/red-hat...-v-foundation/
ชิปหายผุ้สนับสนุนเยอะมากและคุ้นหน้าคุ้นตาในวงการกันดี
อะลีบาบา ก็หันมาพัฒนา ซีพียู ริคส์วี ขึ้นมาใช้Last edited by micronz; 23 Aug 2020, 05:28:46.Comment
-
กลับมาแปลข่าวสั้นๆ เอาที่อ่านแล้วสรุปจากที่เข้าใจนะครับ
คือ DAPRA หรือศูนย์วิจัยเทคโนโลยีความมั่นคงสหรัฐอเมริกา เซ็นต์สัญญาเป็นพัฯธมิตรกับขอใช้ TECHNOLOGY ARM
ให้กับผู้พัฒนา ในโครงการของ DAPRA ซึ่งหลักก็พวก SENSOR CHIP พลังงานต่ำไปจนถึง ระบบควบคุมอาวุธ และ HPC
เพื่อสนับสนุนผู้วิจัยน่ะครับ มันแสดงให้เห็นถึงความก้าวหน้าของ ARM-RISC CHIP ต่างๆแล้ว ยังแสดงให้เห็นว่า
ทางรัฐบาลสหรัฐลดบทบาท INTEL ไปมากแล้วครับ หลังจาก LLNL - Lawrence Livermore National Laboratory
เองก็สั่ง CLAY-IBM ให้พัฒนา Super computer ที่ใช้ AMD EPYC และ POWER 10 รวมทั้ง MARVELL X64 ด้วย
Comment
-
-
น่าจะ และก็กระจายความเสี่ยงออกไปน่ะครับComment
-
ตามลิ้งค์เลย ข่าวจาก ocz คาด Apple A14X Bionic แรงเท่า Core i9-9880H
Comment
-
ผลทดสอบ A14(X) น่าประทับใจ แรงขึ้นมากจริงๆ กินไฟก็น้อยกว่าด้วย แต่สำหรับผม ผมไม่แปลกใจกับผลที่ออกมาเลยOriginally posted by micronz View Post
ชิพ Ax ของ Apple ถูกออกแบบเพื่อตลาด Hi-end Consumer โจทย์การออกแบบคือ ต้นทุนแพงไม่ว่า ข้อให้สมรรถนะสูง+กินไฟต่ำ เหนือคู่แข่งทุกรายในตลาดชิพมือถือ, แทบเล็ต Apple จัดเต็มใส่ Front end, Execution unit, Cache และ IP block มาเต็มที่ ขนาดชิพนี่ใหญ่พอๆกับชิพ CPU desktop เลย

รูป Block Diagram ของชิพ Apple A12
เทียบกันคอร์ต่อคอร์แล้ว A12 คอร์ Vortex ของ A12 น่าจะใหญ่กว่า Zen2 ซะอีก (การผลิต 7nm เหมือนกัน)
A12: Core = 2 (Vortex) +4 (Tempest), Die size = 83.27 mm², with GPU
Zen2 (Compute Die): Core/Thread = 8c/16t, Die size = 74 mm², no GPU
Renoir: Core/Thread = 8c/16t, 156 mm² die size, with GPU
อ้างอิง
https://en.wikichip.org/wiki/amd/mic...tectures/zen_2Comment
-
นับถือ apple จริงๆๆ ครับ apple ถือเป็นผุ้เปลี่ยนแปลงโลกโดยแท้จริงหวังว่าในอนาคต
สินค้าแอปเปิ้ล จะถูกกว่าเดิมราคานะครับหวัง ว่า ท่าน นกแสก 55
อย่างแทบเล็ตมือถือแอปเปิ่ลนี่เห้นชัดเลยว่าเก่าแล้วใช้งานได้ดีต่างกับแอนดรอยด์ที่
กินแรมกว่าเยอะ แรมสองจิ้ก ยุคนี้ไม่พอลแล้วจริงๆๆแต่แอปเปิ้ลทำได้Comment
-
(เสริม)
ผมมองว่าโจทย์การออกแบบของอินเทลและ AMD เน้นกลุ่ม Server เป็นสำคัญ ซึ่งโครงสร้าง big.LITTLE แบบใน A12 ไม่จำเป็นกับ Server เท่าไหร่ โดยเฉพาะพวก VM เพราะ Server ที่ใช้งานจริงจังมีโหลดอยู่เกือบตลอดเวลา คือมันไม่ค่อย idle อยู่แล้ว ออกแบบให้มีคอร์เยอะๆ + SMT ดูจะเหมาะสมกว่า ฝั่ง software และ OS ก็รองรับง่ายกว่า ด้วยเหตุนี้อินเทลและ AMD จึงออกแบบคอร์ให้ใหญ่เหมือน Vortex ไม่ได้ ไม่งั้นจะเพิ่มคอร์เยอะๆได้ยาก และต้นทุนเพิ่มขึ้นมากด้วยComment
-
เอากันที่อินเทลก่อนนะครับ อินเทลเจาะทุกตลาดแต่ เป้นจ้าวตลาด SERVER หลังจากได้ AMD 64 มาแล้วกลับไปผุ้่ไล่ล่า
นำพาตลาด X86 เข้าสู่ Server และปักหลักไดั้จริงจังในขณะที่ AMD เพลี่ยงพล้ำครับ
แอปเปิ้ลไม่ไดั้เน้นตลาด server อยู่แล้วเดี่ยวค่อยแนะนำ core ARM ทีลุยในตลาด server มาคุยกันครับ
ส่วนตัวเห้นว่าไกลตัวเลยไม่ค่อยได้คุยกัน การออกแบบ Big little ผมไม่แน่ใจนะว่าอนาคตจะไปสู่ตลาด
server ใหม่แต่ก่อนหน้ามีตัว ARM server ที่แรงประหยัดไฟอยู่เช่นกัน แต่ตอนนี้ Qualcom อ่อนแรงไปเยอะ
จะเป้นหัวเว่ยที่มาลุยตลาดนี้ก็โดนเตะตัดขา แต่ ตลาด arm server มีผุ้เล่นอยุ่ครับนอกจา ควอลคอม ค่อยมาขยายกันต่อComment
-
เรื่องการใช้แรม ผมว่า CPU ไม่ค่อยมีส่วนเท่าไหร่ เป็นผลมาจาก 2 สิ่งนี้มากกว่าOriginally posted by micronz View Post- การอ๊อพติไมซ์ฝั่งซอฟแวร์และ OS
- ติดตั้ง SSD และ Controller ที่เร็วมาก ทำให้แม้บางครั้งแรมหมดก็ไม่รู้สึกหน่วง เท่าที่ผมรู้มา Apple ประยุกต์ใช้บัส PCI-e กับ SSD ในมือถือก่อนใครเพื่อน ก่อนจะมีมาตรฐาน USF ซะอีก
Comment
-
เป้นผลจาก ios ครั้บ การจัดการ memory มันคนละแนวกับ แอนดรอยด์
ทำให้แรมน้อยๆๆก็ใช้ได้ดีครับ แอนดรอยด์ แรมสองจิ้กไม่รอดแน่ ของผมอืดชิปหายรอเปลี่ยนห้าจีทีเดียว
แต่ไอโฟน แรมสองจิ้กเล่นได้ดีนะLast edited by micronz; 26 Aug 2020, 11:56:40.Comment
-
ตามนี้ครับ ที่เคยบอก จะ RISC หรือ CISC มันก็ขึ้นกับ CU group ครับ ตราบเท่าที่เป็น DIGITAL LOGICOriginally posted by นกแสก View Post
ที่ใช้ TR ไม่ใช่ Quantum มันก็อยู่บน BASIC LOGIC Group arangement ใส่ไปเท่าไหร่ IPC มันก็ได้ตามนั้น
ซึ่ง ARM ทุกตัว มอง Core เฉยๆไม่ได้ ต้องมองทุก UNIT เลย เพราะมันทำงานช่วยๆกันไป ตามผังนั้นแหละ
IOS Implement มาใช้ทุกส่วนได้ดีกว่า android มันก็แรงแซง X86 ได้ android+crome os+WIN ARM ก็ทำได้ แต่ต้องให้เวลาเค้าพัฒนา OS kernel กันไป
เหลือ software เท่านั้นเอง เลยต้อง Transition 2 ปี ให้ฝั่ง SW มีเวลาหายใจComment
-
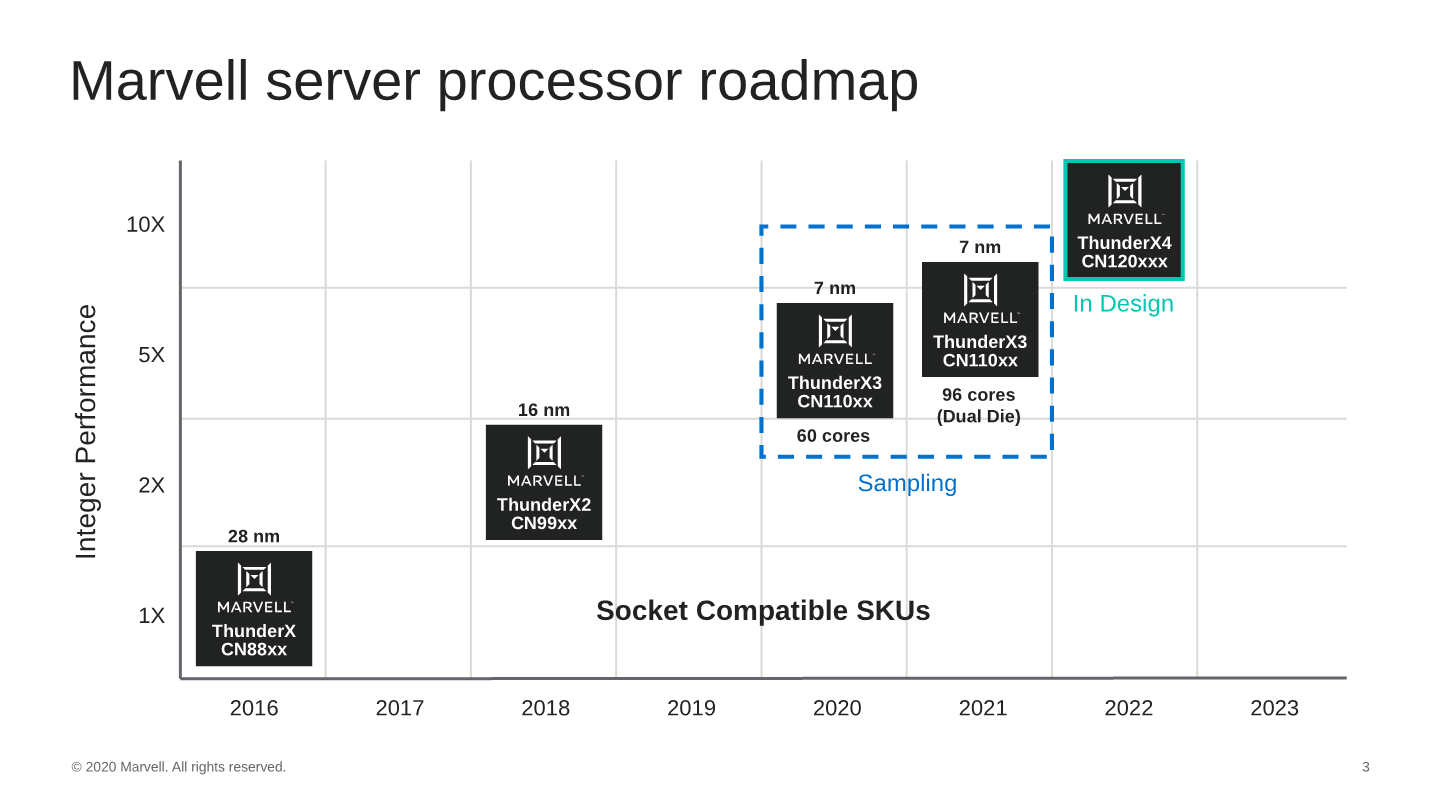
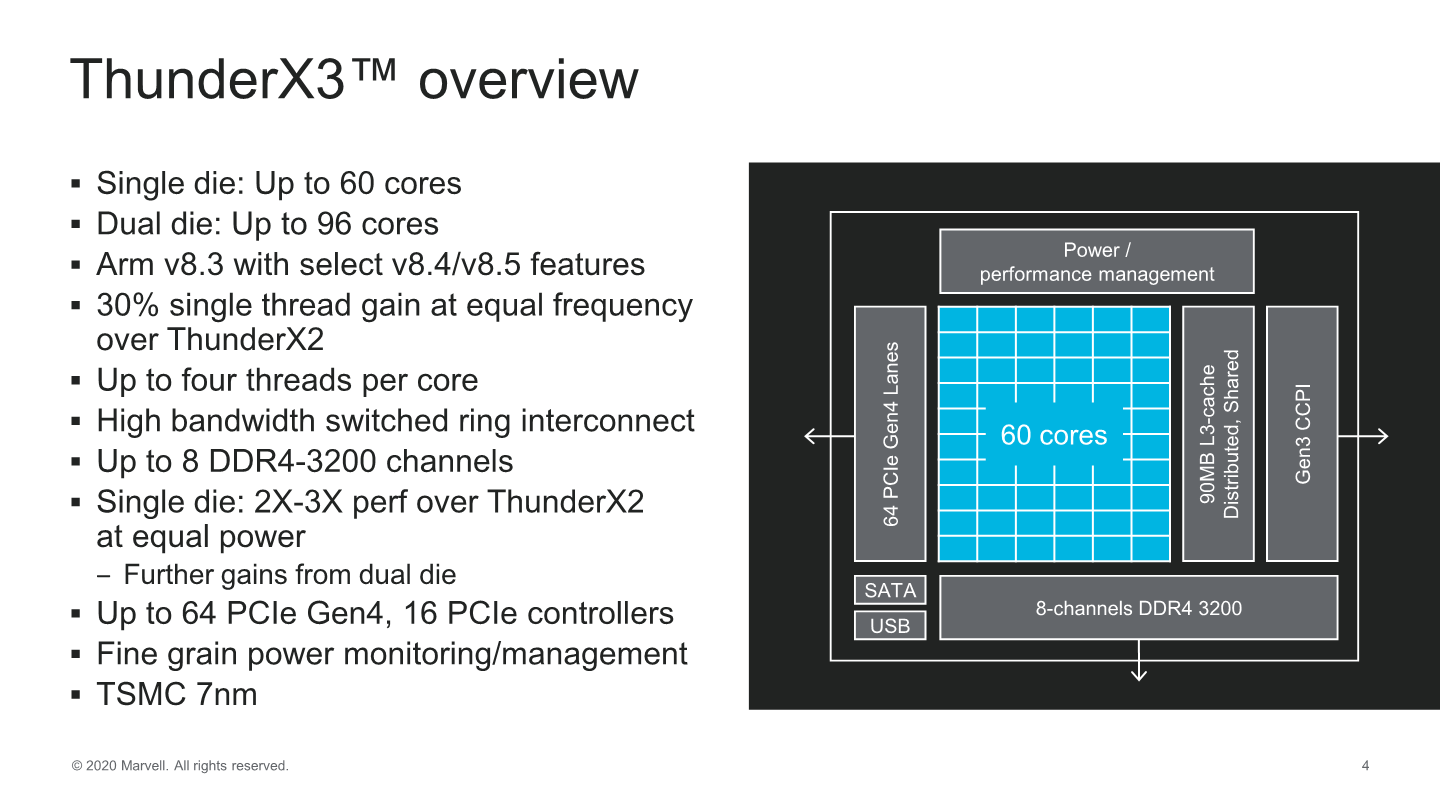
Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
สาย Server สำคัญๆ ตัวนึงก็เจ้านี่แหละ และ เป็นส่วนหนึ่งของ VANGUARD Project ด้วย
https://www.anandtech.com/show/15995...ls-thunderx3/2
by Andrei Frumusanu on August 17, 2020 4:30 PM EST
Up to 60 Cores Per Die, 96 Dual-Die in 2021 Triton CPU Core - 30% Generational IPC Improvements SMT4 and Performance Projections - First Impressions

Today as part of HotChips 2020 we saw Marvell finally reveal some details on the microarchitecture of their new ThunderX3 server CPUs and core microarchitectures. The company had announced the existence of the new server and infrastructure processor back in March, and is now able to share more concrete specifications about how the in-house CPU design team promises to distinguish itself from the quickly growing competition that is the Arm server market.
We had reviewed the ThunderX2 back in 2018 – at the time still a Cavium product before the designs and teams were acquired by Marvell only a few months later that year. Ever since, the Arm server ecosystem has been jump-started by Arm’s Neoverse N1 CPU core and partner designs such as from Amazon (Graviton2) and Ampere (Altra), a quite different set of circumstances and alongside AMD’s successful return in the market, a very different landscape.
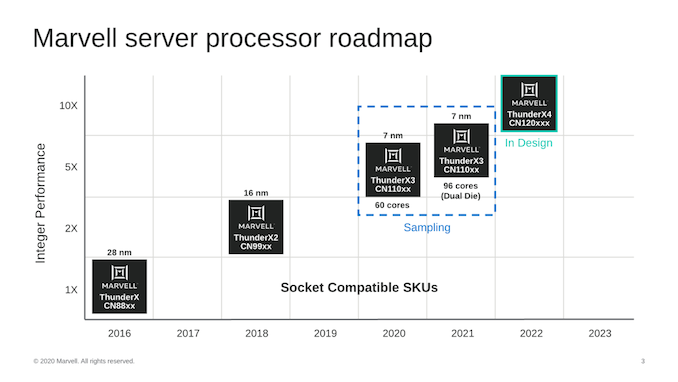
Marvell started off the HotChips presentation with a roadmap of its products, detailing that the ThunderX3 generation isn’t merely just a single design, but actually represents a flexible approach using multiple dies, with the first generation 60-core CN110xx SKUs using a single die as a monolithic design in 2020, and next year seeing the release of a 96-core dual-die variant aiming for higher performance.
The use of a dual-die approach like this is very interesting as it represents a mid-point between a completely monolithic design, and a chiplet approach from vendors such as AMD. Each die here is identical in the sense that it can be used independently as standalone products.
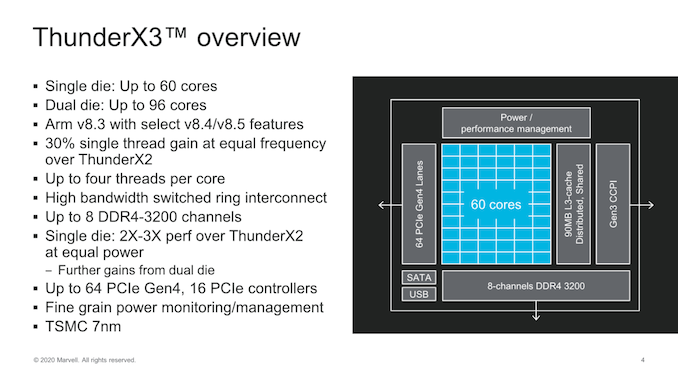
From a SoC-perspective, the ThunderX3 die scales up to 60 cores, with the 2-die variant scaling up to 96. The first thing question that comes to mind when seeing these figures is why the 2-die variant doesn’t scale up to the full 120-cores- Marvell didn’t cover this during the talk but there were a few clues in the presentation.
Marvell had made the performance improvement claim of 2-3x over a ThunderX2 at equal power levels. This latter had a TDP of 180W – if the TX3 maintains this thermal envelope then it would mean that a dual-die design would have had to grow TDPs to up to 360W which far beyond what one can air cool in a typical server form-factor and rack in terms of power density. Assuming just a linear cut-down to 96 cores as advertised we’d end up around 288W – which is more in line with the current high-end server CPU deployments without water-cooling. Of course – this is all our own analysis and take of the matter.
A single die supports 8 channels of DDR4-3200 which is standard for this generation of a server product and essentially in line with everybody else in the market. I/O wise, we see a disclosure of 64 lanes of PCIe 4.0 – which is again in line with competitors but half of what higher-end alternatives from Ampere or AMD can achieve.
One big unknown right now is how the dual-die product will segment the I/O and memory controllers – if this is going to be a 50-50 split in terms of resources between the two dies, or whether we’ll see an imbalanced setup – or if the platform can actually handle the full resources from each die and transform itself into a 16-channel 128 lane beast?On paper at least, the ThunderX3 seems quite similar to Amazon’s Graviton2 as they both share a similar amount of CPU cores and similar memory and IO configurations. The bigger differences that one can immediately point out to is that the ThunderX3 employs SMT4 in its CPU cores and thus supports up to 240 threads per die. There’s also a TDP difference, but I attribute this to the Graviton2 being conservative with its clock frequencies, whilst Ampere’s SKUs being more in line with the ThunderX3, particularly the 64-core 3.0GHz 180W Q64-30 being the closest match in specifications.Comparison of Major Arm Server CPUs Marvell
ThunderX3
110xxCavium
ThunderX2
9980-2200Ampere
Altra
Q80-33Amazon
Graviton2Process Technology TSMC
7nmTSMC
16 nmTSMC
7 nmTSMC
7nmDie Type Monolithic
or
Dual-Die MCMMonolithic Monolithic Monolithic Micro-architecture Triton Vulcan Neoverse N1 (Ares) Cores 60 (1 Die)
Swiched 3x Ring
96 (2 Die)32
Ring bus80
Mesh64
MeshThreads 240 (1 Die)
384 (2 Die)128 80 64 Max. number of sockets 2 2 2 1 Base Frequency ? 2.2 GHz - - Turbo Frequency 3.1 GHz 2.5 GHz 3.3 GHz 2.5 GHz L3 Cache 90MB 32 MB 32 MB 32 MB DRAM 8-Channel
DDR4-32008-Channel
DDR4-26678-Channel
DDR4-32008-Channel
DDR4-3200PCIe lanes 4.0 x 64
(1 Die)3.0 x 56 4.0 x 128 4.0 x 64 TDP ~180W (1 Die)
(unconfirmed)180W 250 W ~110-130W
(unconfirmed)
Another thing that stands out for the ThunderX3 is the 90MB of L3 cache that dwarfs the 32MB of the previous generation as well as the 32MB configurations of Ampere and Amazon.
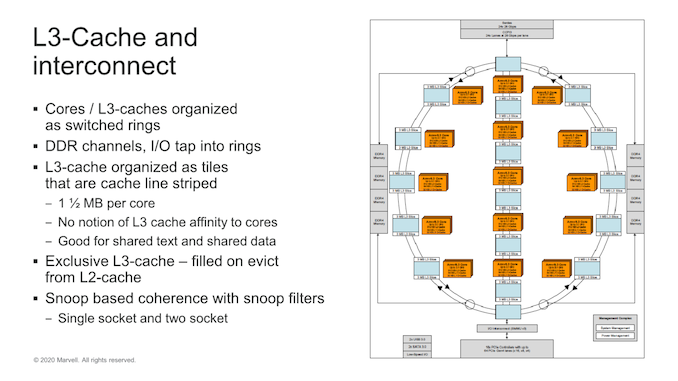
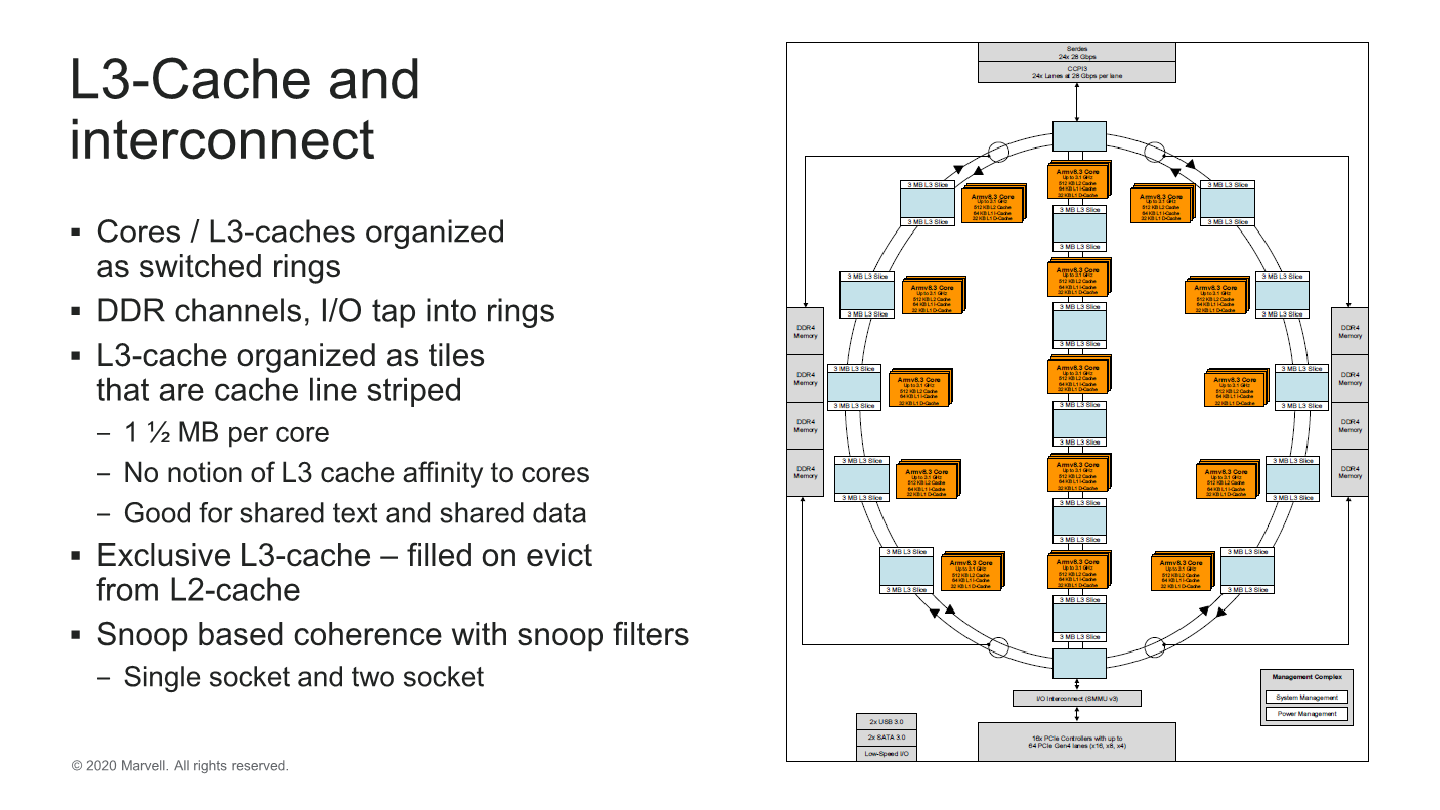
Marvell here opted to evolve its own interconnect microarchitecture which has now evolved from a simple ring design, to a switched ring with three sub-rings, or columns. Ring stops consist of CPU tiles with 4 cores and two L3-slices with 3MB of cache. This gives a full die with 15 ring stops (3x5 columns) and the full 60 cores 90MB of total L3 cache which is a quite respectable amount.
In the Q&A sessions, Marvell disclosed that their rationale for a switched ring topology versus a single ring, or a mesh design was that a single ring wouldn’t have been able to scale up in performance and bandwidth at higher core counts. A mesh design would have been a big change, and it would have required a reduction in core count. A switched ring represented a good trade-off between the two architectures. Indeed, if this is what enabled Marvell to include up to 3x the cache versus its nearest competitors, it seems to have been a good choice.
One odd thing I noted is that the system is still using a snoop-based coherency algorithm which comes in contrast with other directory-based systems in the industry. This might reduce implementation complexity and area, but might lag behind in terms of power efficiency and coherency traffic for the chip.
The memory controllers tap into the rings, and Marvell’s inter-socket/die CCPI3 interface here serves up to 84GB/s of bandwidth.Comment



Comment