 Tweet
Tweet
-ของก๊อปทำไมมันโหดจังมันโหดกว่าชาวบ้านเค้า
-7nmปลอมทำไมมันโหดจังมันโหดกว่าชาวบ้านเค้า
-7nmปลอมทำไมมันโหดจังมันโหดกว่าชาวบ้านเค้า



 ว่าไปนั่น
ว่าไปนั่น  ว่าแต่ จารย์บ้าโอ หายไปใหนนะ สงสัยงานหนัก ช่วงนี้นักเรียนต้องตรวจ Covid ก่อนเข้าเรียน
ว่าแต่ จารย์บ้าโอ หายไปใหนนะ สงสัยงานหนัก ช่วงนี้นักเรียนต้องตรวจ Covid ก่อนเข้าเรียน
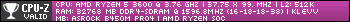




Comment