 Tweet
Tweet

AMD Zen3 และ Intel Rocket Lake ต่างก็เป็น CPU ที่ชาวคอมพ์ต่างสนใจเนื่องจากเป็นเจนใหม่และเป็นสถาปัตยกรรมใหม่ ซึ่งที่ผ่านมาก็มีข้อมูล-ข่าวหลุดเผยแพร่ออกมาบ้างแล้วตามเว็บ IT ทั้งหลาย ซึ่งคราวนี้ผมจะมาพูดคุยในประเด็นชุดคำสั่ง "AVX" โดยทางฝั่ง Intel Rocket Lake (มีพื้นฐานจาก Willow Cove) จะรองรับ AVX512 ขณะที่ AMD Zen3 แม้จะยังไม่ยืนยันว่าจะรองรับแค่ AVX2 เหมือนเดิมหรือจะเพิ่ม AVX512 เข้ามา แต่ผมค่อนข้างแน่ใจว่า Zen3 จะยังไม่รองรับ AVX512 (หรืออาจไม่รองรับไปตลอดกาลเลยก็ได้) เนื่องจากทิศทางการพัฒนาของ AMD รวมถึงอุปสรรคบางอย่าง ซึ่งถ้ามีโอกาสจะเล่าในภายหลัง
ถึงตรงนี้หลายคนคงเริ่มมองออกว่าหาก Zen3 รองรับแค่ AVX2 ขณะที่ Rocket Lake รองรับ AVX512 ย่อมเกิดความเหลื่อมล้ำในคะแนนผลทดสอบ (Benchmark) อย่างแน่นอน
ใช่แล้วครับ เหลื่อมล้ำแน่ๆ ลำพัง AVX2 ปะทะ AVX512 ก็หนักแล้ว แล้วยิ่งถ้า Benchmark ไหนเรียกใช้คำสั่งใหม่ๆใน AVX512 โดยไม่เผื่อทางเลือกสำรองให้ใช้ชุดคำสั่ง AVX รุ่นเก่าทดแทนเลย ก็ยิ่งไปกันใหญ่ เพราะเท่ากับว่า Rocket Lake จะได้พลังจาก AVX512 เต็มๆและจะมีคะแนนพุ่งกระฉูด ขณะที่ CPU อื่นต้องทำงานตามมีตามเกิดด้วยชุดคำสั่ง x86 ปกติ โดยไม่มี AVX ใดๆมาช่วยทั้งสิ้น (แม้จะรองรับ AVX2 ก็ตาม) และจะมีคะแนนที่ดูน่าอนาถ
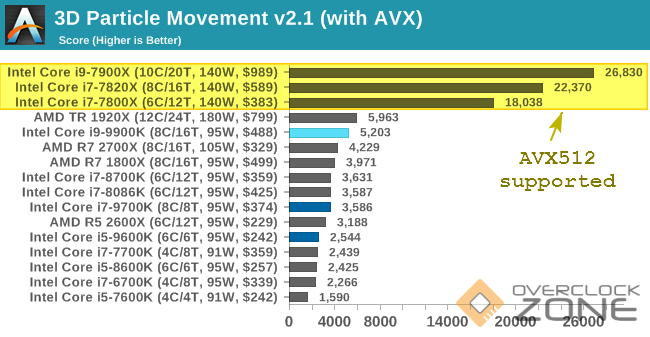
รองรับ AVX512 กับไม่รองรับ มันเหลื่อมล้ำกันขนาดนี้... (รูปจากเว็บ Anandtech)
เมื่อเป็นแบบนี้ทั้งสื่อ IT และผู้บริโภคเองก็อาจโดน Benchmark ชี้นำผิดๆและแนะนำเลือกซื้อ CPU โดยที่ไม่ได้ประโยชน์จากมันอย่างที่คาดหวัง แนวทางที่พอจะช่วยได้คือ
- AMD คงต้องหาทางแก้เกม เพราะนี่เป็นผลประโยชน์ของบริษัทเอง
- สื่อ IT ควรนำเสนออย่างรู้เท่าทัน เพื่อประโยชน์ของผู้อ่าน อันที่จริงมี Benchmark บางตัวสามารถเลือกเปิด/ปิดการใช้งาน AVX ได้ ซึ่งผมเชื่อว่าสื่อ IT ที่เข้าใจแง่มุมนี้ จะนำเสนอเปรียบเทียบทั้ง 2 กรณีพร้อมให้คำอธิบาย ซึ่งที่ผ่านมาผมเห็นสื่อฝรั่ง 2 รายคือ Tomshardware และ Anandtech ที่ทำแบบนี้ (แต่เชื่อเถอะ มีผู้อ่านจำนวนมากที่ดูแต่กราฟ โดยไม่ได้อ่านคำอธิบาย) หวังว่าเมื่อถึงเวลา สื่อของไทยจะเข้าใจแง่มุมนี้และนำเสนออย่างรู้เท่าทันเช่นกัน
- พวกเราชาวคอมพ์เองก็ควรรู้ทันการตลาด ดูกราฟอย่างมีสติ แยกแยะว่าอันไหนเป็นสมรรถนะจริง อันไหนได้มากจาก AVX จะได้แนะนำคนอื่นได้อย่างเหมาะสม
(มีต่อ)








Comment